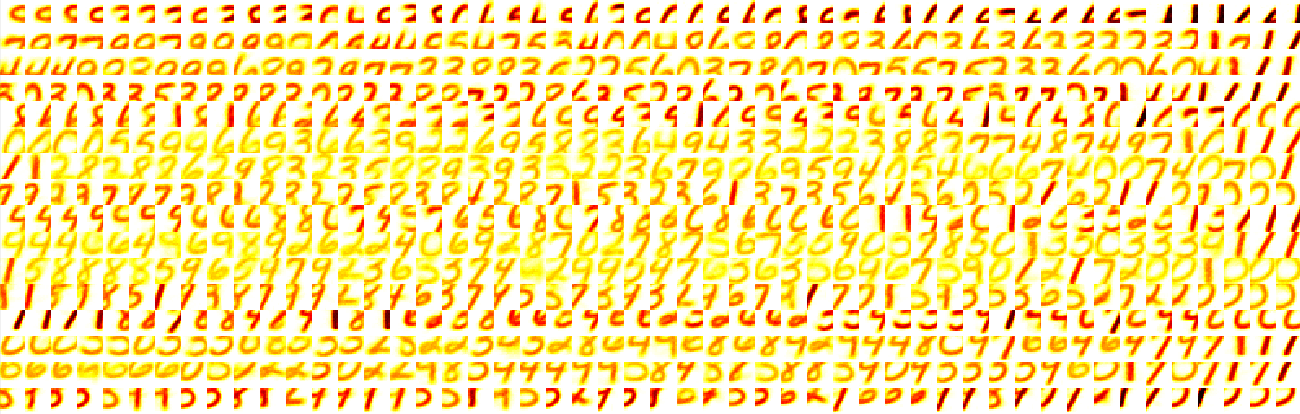Machine Learning with Spike-Timing-Dependent Plasticity
Outline:
The current dominating approach to artificial intelligence, deep learning, uses global gradient-based learning, which is demanding in terms of computation time and memory requirements. We implemented a prototype local spike timing dependent plasticity (STDP) learning algorithm that is an alternative or even complementary approach to global learning. We show that this approach scales well, and it can reduce drastically the computational demand of deep learning with many computational layers and with many millions of parameters.
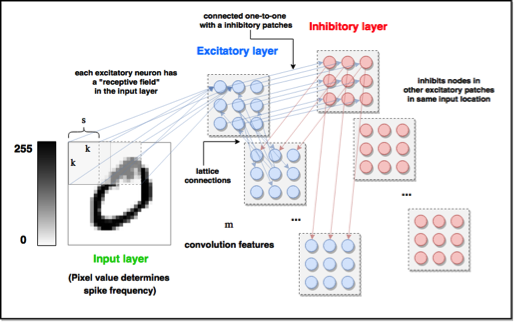
Convolution spiking neural network (C-SNN) architecture. The input is quantized into overlapping, regularly sized and spaced windows, which are project to a chosen number of excitatory neuron populations (patches). Each excitatory neuron is connected to a unique neuron in a collection of inhibitory neuron populations, which connect to all other excitatory neurons which have the same input receptive field. Weights on the connections between input and excitatory patches are modifiable with an STDP learning rule.
Weights learned from C-SNNs in which convolution size is 16, the stride is 4, and there are 50 convolution patches. Top: Weights within a convolution patch sub-population are constrained to be equal. Features are learned that may appear in any location in input space. Bottom: Weights within a convolution patch are allowed to evolve independently. Features are learned which correspond to particular locations in input space.
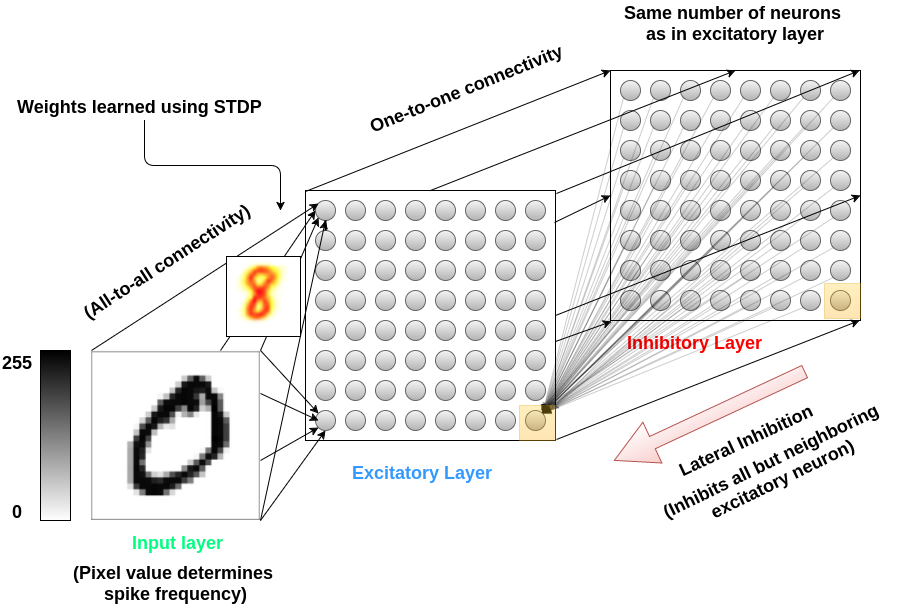
Spiking neural network architecture used for SNN baseline and LM-SNN experiments. Input pixels are encoded as Poisson-distributed spike trains, and is connected all-to-all with modifiable synapses to a layer of excitatory neurons. Excitatory neurons are mapped one-to-one with a layer of inhibitory neurons, which connect back to all excitatory neurons, except to the neurons from which they receive their connections. The SNN baseline stipulates that all inhibitory synapses are of equal strength; the LM-SNNs removes this requirement, allowing inhibitory synapse strengths to vary as a function of inter-neuron distance.
Left: Self-organized full-image filters learned using spike-timing-dependent plasiticity and two distinct levels of lateral inhibition. The first level of inhibition is low but increasing with inter-neuron distance; filters self-organize into clusters of similar data representations. The second level is high, and each neuron inhibits all others equally when it fires, leading to the individualize and fine-tuning of filters. Right: Corresponding MNIST labels, set using spiking activity on a subset of the training data. Clustered and more individualized areas of the filter map are evident from this visualization.